😄 About Me
I have been a Ph.D. candidate at the School of Integrated Circuits, Shanghai Jiao Tong University (SJTU), since September 2022, under the supervision of Prof. Lei He (IEEE Fellow). I am also a research intern at the Eastern Institute of Technology (EIT), Ningbo. I obtained my B.S. and M.S. degrees in integrated circuit design at Xidian University.
🎯 Research Interests
- Digital IC Design for AI Chips
- Hardware/Software Co-Optimization
- AI Compiler Development
- FPGA-Based Accelerator
- AI Models:Llama,dLLM,Mamba,VLA
🎓 Education
-
Shanghai Jiao Tong University (2022.09 – 2026.06)
Ph.D. in Integrated Circuits Engineering -
Xidian University (2019.09 – 2022.06)
Master’s in Integrated Circuit Design -
Xidian University (2015.09 – 2019.06)
Bachelor’s in Integrated Circuit Design and Systems
🏆 Awards
- 2025.11: 🏅 1st Prize, the Build Your Dreams (BYD) Scholarship, Shanghai Jiao Tong University — Rank 3/160,
- 2021.12: 🥉 3rd Prize, the 4th “Huawei Cup” China Graduate Chip Innovation Competition, Special Second Prize GalaxyCore Technology Co., Ltd — Rank 50/499,
- 2021.07: 🏅 3rd Prize, the 5th National College Student Integrated Circuit Innovation and Entrepreneurship Competition— Northwest Region, Rank 57/180
- 2020.10: 🥈 2nd Prize, the 3rd “Huawei Cup” China Graduate Chip Innovation Competition, Special First Prize S2C Technology Co., Ltd — Rank 24/453,
- 2020.09: 🏅 1st Prize (twice), 2nd Prize (once), Study Excellence Scholarship for Master’s Degree Candidates, Xidian University — Rank 4/188,
📚 Publications
- [1] CCF-A ASPLOS 2026 DFVG: A Heterogeneous Architecture for Speculative Decoding with Draft-on-FPGA and Verify-on-GPU. Shaoqiang Lu*, Yangbo Wei*, Junhong Qian, Dongge Qin, Shiji Gao, Yizhi Ding, Qifan Wang, Chen Wu, Xiao Shi, Lei He.
- [2] CCF-A DAC 2025 MambaOPU: An FPGA Overlay Processor for State-space-duality-based Mamba Models. Shaoqiang Lu*, Xuliang Yu*, Tiandong Zhao, Siyuan Miao, Xinsong Sheng, Chen Wu, Liang Zhao, Ting-Jung Lin, Lei He.
- [3] CCF-B ICCAD 2025 MoE-OPU: An FPGA Overlay Processor Leveraging Expert Parallelism for MoE-based Large Language Models. Shaoqiang Lu*, Yangbo Wei*, Junhong Qian, Chen Wu, Xiao Shi, Lei He.
- [4] CCF-B TRETS Journal 2025,ISEDA 2024 MCoreOPU: An FPGA-based Multi-Core Overlay Processor for Transformer-based Models. Shaoqiang Lu*, Tiandong Zhao*, Ting-Jung Lin, Rumin Zhang, Chen Wu, Lei He.
- [5] CCF-B ICCAD 2024 ChatOPU: An FPGA-based Overlay Processor for Large Language Models with Unstructured Sparsity. Tiandong Zhao, Shaoqiang Lu, Chen Wu, Lei He.
- [6] CCF-C ASAP 2025 (Best Paper Nomination)👉 METAL: A Memory-Efficient Transformer Architecture for Long-Context Inference on FPGA. Zicheng He, Shaoqiang Lu, Tiandong Zhao, Chen Wu, Lei He.
- [7] CCF-C ASP-DAC 2026 dLLM-OPU: An FPGA Overlay Processor for Accelerated Diffusion Large Language Models. Yangbo Wei*, Shaoqiang Lu*, Junhong Qian, Chen Wu, Xiao Shi, Lei He.
- [8] CCF-C FPT 2026 FlightOPU: An FPGA Overlay Processor for LLM with HBM-Aware Multi-Die Architecture. Chen Wu, Shaoqiang Lu, Yangbo Wei, Junhong Qian, Jinlong Yan, Zhanfei Chen, Rumin Zhang, Xiao Shi, Lei He.
- [9] CCF-A AAAI 2026 Mixture-of-Trees: Learning to Select and Weigh Reasoning Paths for Efficient LLM Inference. Yangbo Wei, Zhen huang, Shaoqiang Lu, Junhong Qian, Dongge Qin, Ting Jung Lin, Wei Xing, Chen Wu, Lei He.
- [10] CCF-C FPL 2023 Token Packing for Transformers with Variable-Length Inputs. Tiandong Zhao, Siyuan Miao, Shaoqiang Lu, Jialin Cao, Jun Qiu, Xiao Shi, Kun Wang, Lei He.
- [11] CCF-C FCCM 2025 C2OPU: Hybrid Compute-in-Memory and Coarse-Grained Reconfigurable Architecture for Overlay Processing of Transformers. Siyuan Miao, Lingkang Zhu, Chen Wu, Shaoqiang Lu, Jinming Lyu, Lei He.
- [12] CCF-A Science China: Information Sciences 2025 FPGA Overlay processor for AI computing. He Lei, Wang Kun, Wu Chen, Tao Zhuofu, Shi Xiao, Miao Siyuan, Shaoqiang Lu.
🧰 Projects
Project 1: An FPGA-based Overlay Processor Unit for Accelerating AI Models
Description
- Designed an FPGA-based Overlay Processor Unit (OPU) to accelerate inference of diverse AI deep learning models. Optimized data flow and operator execution through hardware–software co-design. Successfully deployed in real-time edge scenarios.
Responsibilities
- Designed the OPU including the instruction set, compiler, and hardware microarchitecture.
- Built a scalable computing engine for parallel execution of key operations (e.g., convolution, matrix multiplication).
- Developed specialized functional units for nonlinear operations.
- Implemented a real-time hardware–software runtime, covering CPU-side model compilation to FPGA inference.
- Enabled PCIe-based transfer of weights and control instructions.
- Designed for scalability across various sizes and types of neural networks.
Experimental Setup
- Xilinx Alveo U200 @ 300 MHz (PE 600 MHz)
- Implementation 4-Core OPU + 64 GB DDR4
- Quantization Models run INT8 bitsandbytes.
Evaluation
- Resources Usage (left) vs. Model Results (right) * We report the first token latency.
| Resource | LUT | FF | BRAM | DSP | Model | BERT | ViT | GPT2 | LLaMA7B | |
|---|---|---|---|---|---|---|---|---|---|---|
| Used | 947684 | 1806396 | 1004 | 4364 | Latency* (ms) | 3.41 | 6.96 | 59.49 | 149.57 | |
| Util(%) | 80.1% | 76.3% | 46.5% | 63.8% | Throughput (TOP/s) | 6.08 | 4.66 | 7.42 | 7.99 |
Tools
- Vivado , FPGA (U200) , Verilog , ModelSim , PCIe , DDR , XDMA , C++ , Python , PyTorch
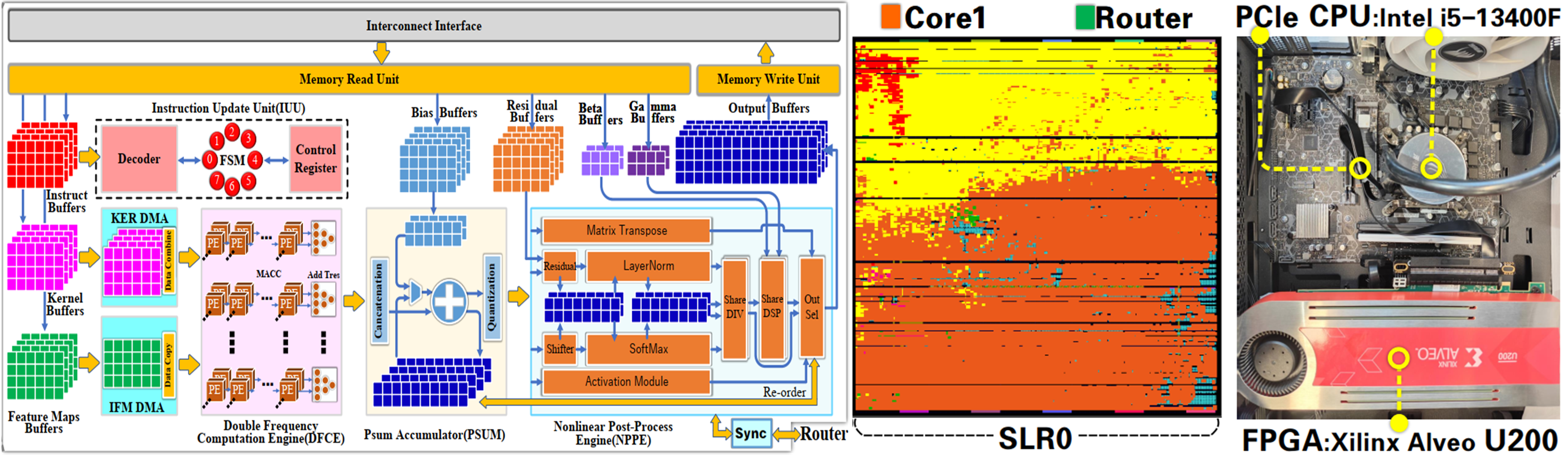
Demo
Project 2:A Edge SoC with co-Accelerator in ARM Cortex-M3 for Face Detection
Description
- Developed an Edge System-on-Chip (SoC) integrating an ARM Cortex-M3 processor with a dedicated hardware co-accelerator to enable real-time face detection. Deploy a decision-tree–based PICO (Pixel-Intensity Comparison-based Object Detection) model.
Responsibilities
- Built a complete image acquisition, storage, and display pipeline with Bus peripheral access in software.
- Implemented the face detection algorithm on Cortex-M3 for standalone execution.
- Designed and integrated a dedicated hardware accelerator to boost detection performance.
- Ran on a 100 MHz AX7103 FPGA with OV5640 (3-million-pixel) for image capture.
- Data is stored in DDR3, HDMI for real-time display, and UART for status communication.
Experimental Setup & Results
- Camera: OV5640, RGB565, 5 MP ; Display: HBMI, RGB888, 640×480 @ 60 Hz ; Memory: DDR3 ×2 (8 Gb each).
| Resource | Used | Utilization | SMIC55 | Report | Platform | Implement | Latency | ||
|---|---|---|---|---|---|---|---|---|---|
| LUT | 36583 | 57.70% | ASIC Area | 61801 μm² | CPU | OpenCV | 33 ms | ||
| FF | 36130 | 28.50% | PT Power | 361.5 μW | FPGA | RTL | 42 ms | ||
| BRAM | 101 | 75.00% | NAND2 area | 1.12 μm²/gate | Cortex-M3 | C | 2,700 ms | ||
| DSP | 27 | 11.00% | Gates/MOScount | 55180/ ≈220k | Speedup | Cortex/FPGA | ≈ 60x |
Evaluation
- Achieved 41 ms/face processing time with hardware acceleration, compared to 2700 ms/face on pure Cortex-M3.
- Delivered a 65.81× performance speedup over the baseline software-only implementation.
Tools & Technologies
- C (embedded Cortex-M3) , AHB/APB/AXI , Keil MDK , AX7103 , OV5640 , HDMI
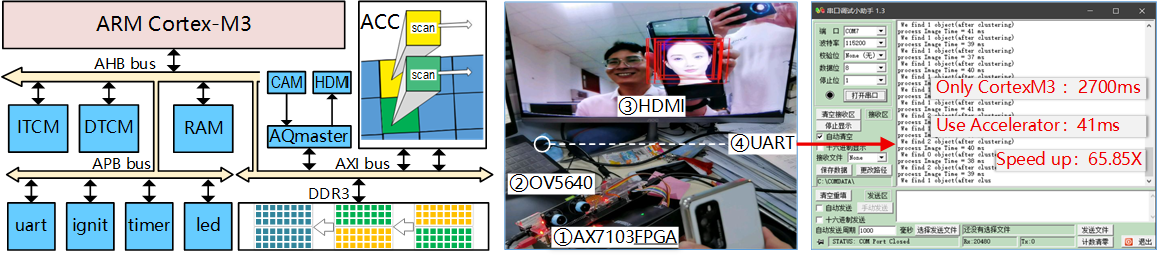
Demo
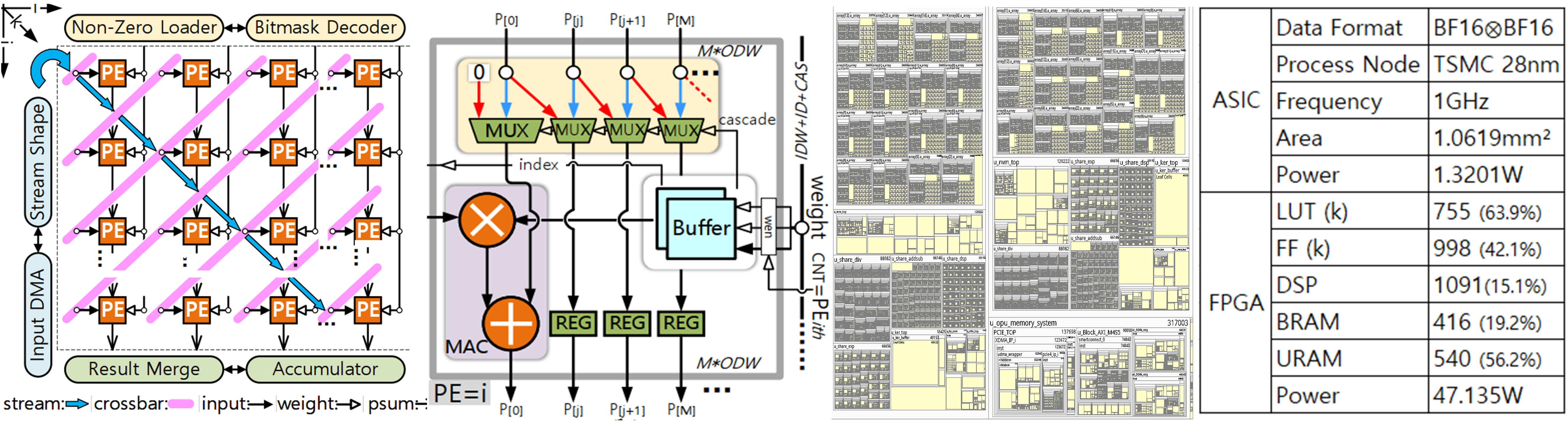
Project 3:Digital IC Frontend Design and Implementation of a PE Array
Description
- Designed a Processing Element (PE) array to accelerate irregular sparse AI workloads. Implemented the digital IC frontend design flow and compared resource utilization between ASIC and FPGA implementations.
Responsibilities
- Designed sparse computing architecture for the PE array, including triangular-fed data flow, PE unit logic, and weight bitmask decoding.
- Verified functionality via simulation before setting timing constraints.
- Completed both FPGA and ASIC flows, eliminating timing violations through iterative analysis.
- Integrated the PE array into a complete accelerator system.
- Analyzed synthesis and power reports to guide RTL refinement for improved performance.
Evaluation
- Logic synthesis using Synopsys Design Compiler (DC) at TSMC 28nm process node.
- Power analysis via PrimeTime (PT), achieving:
- 1 GHz operating frequency
- 1.06 mm² core area
- 1.32 W power consumption
- Balanced performance, area, and power through RTL optimizations.
Tools & Technologies
- Verilog , Synopsys Design Compiler (DC) , PrimeTime (PT) , VCS , TSMC 28nm , SDC , Shell , Tcl
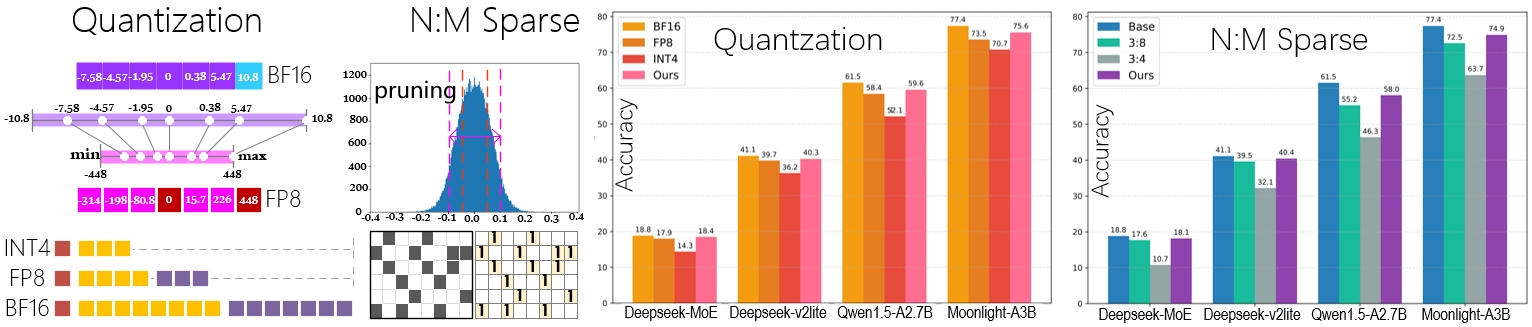
Project 4:Expert-Aware Quantization and Sparsity for MoE- based Models
Description
- Designed and implemented expert-aware quantization and sparsity optimization techniques for Mixture-of-Experts (MoE) models to reduce memory footprint.
Responsibilities
- Introduced N:M sparsity patterns (1:4 / 2:4 / 4:8 / 6:8 / 8:8) in MLP layers.
- Applied mixed-precision quantization (BF16 / FP8 / INT4) guided by expert activation frequency, covering both expert and shared layers.
- Integrated sparsity and quantization pipelines into the training workflow of the DeepSeek-V2-Lite model on the GSM8K dataset.
Evaluation
- Reduced parameter size by up to 2.76× while maintaining accuracy.
- Only 1.53% average accuracy drop after fine-tuning.
- Achieved 2–3× speedup and 40–60% memory savings.
Tools & Technologies
- PyTorch , DeepSeek-V2-Lite , GSM8K dataset , CUDA , NVIDIA A100 , NVIDIA RTX 4090 , Python